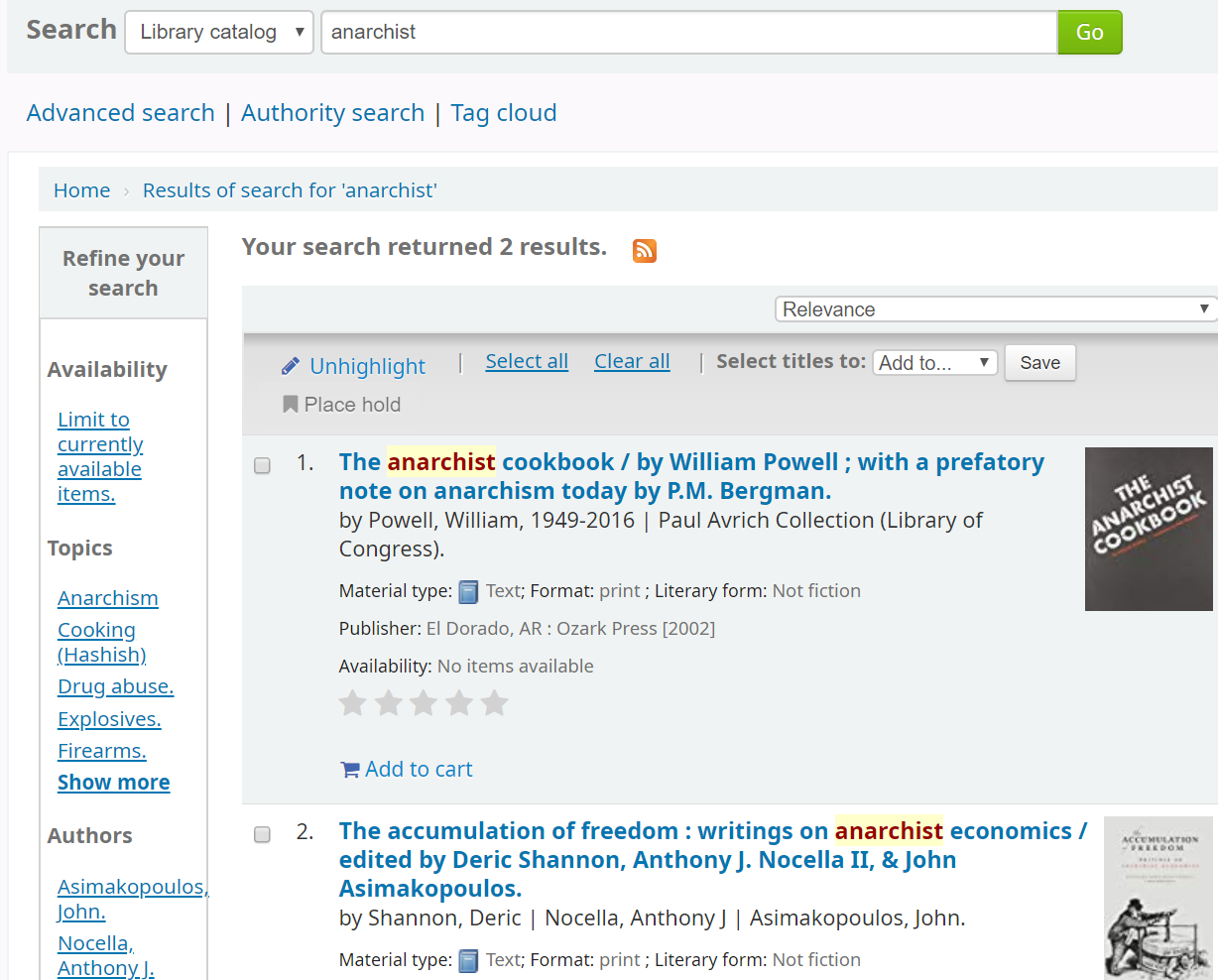
Let’s search a Koha catalog for something that isn’t at all controversial:
What you search for in a library catalog ought to be only between you and the library — and that, only briefly, as the library should quickly forget. Of course, between “ought” and “is” lies the Devil and his details. Let’s poke around with Chrome’s DevTools:
- Hit Control-Shift-I (on Windows)
- Switch to the Network tab.
- Hit Control-R to reload the page and get a list of the HTTP requests that the browser makes.
We get something like this:
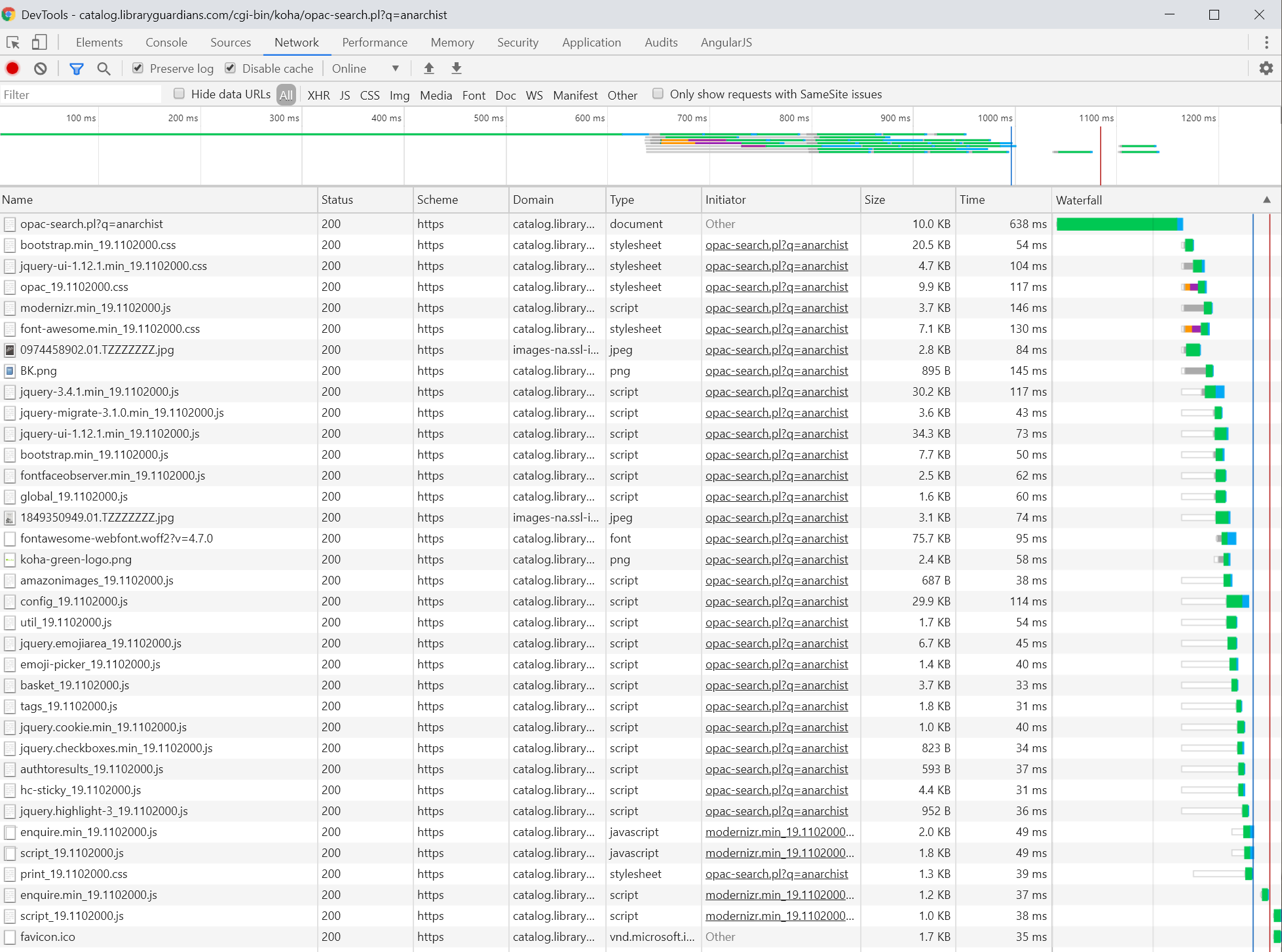
There’s a lot to like here: every request was made using HTTPS rather than HTTP, and almost all of the requests were made to the Koha server. (If you can’t trust the library catalog, who can you trust? Well… that doesn’t have an answer as clear as we would like, but I won’t tackle that question here.)
However, the two cover images on the result’s page come from Amazon:
https://images-na.ssl-images-amazon.com/images/P/0974458902.01.TZZZZZZZ.jpg
https://images-na.ssl-images-amazon.com/images/P/1849350949.01.TZZZZZZZ.jpg
What did I trade in exchange for those two cover images? Let’s click on the request on and see:
:authority: images-na.ssl-images-amazon.com
:method: GET
:path: /images/P/0974458902.01.TZZZZZZZ.jpg
:scheme: https
accept: image/webp,image/apng,image/,/*;q=0.8
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
cache-control: no-cache
dnt: 1
pragma: no-cache
referer: https://catalog.libraryguardians.com/cgi-bin/koha/opac-search.pl?q=anarchist
sec-fetch-dest: image
sec-fetch-mode: no-cors
sec-fetch-site: cross-site
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36
Here’s what was sent when I used Firefox:
Host: images-na.ssl-images-amazon.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0
Accept: image/webp,/
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://catalog.libraryguardians.com/cgi-bin/koha/opac-search.pl?q=anarchist
DNT: 1
Pragma: no-cache
Amazon also knows what my IP address is. With that, it doesn’t take much to figure out that I am in Georgia and am clearly up to no good; after all, one look at the Referer header tells all.
Let’s switch over to using Google Book’s cover images:
https://books.google.com/books/content?id=phzFwAEACAAJ&printsec=frontcover&img=1&zoom=5
https://books.google.com/books/content?id=wdgrJQAACAAJ&printsec=frontcover&img=1&zoom=5
This time, the request headers are in Chrome:
:authority: books.google.com
:method: GET
:path: /books/content?id=phzFwAEACAAJ&printsec=frontcover&img=1&zoom=5
:scheme: https
accept: image/webp,image/apng,image/,/*;q=0.8
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
cache-control: no-cache
dnt: 1
pragma: no-cache
referer: https://catalog.libraryguardians.com/
sec-fetch-dest: image
sec-fetch-mode: no-cors
sec-fetch-site: cross-site
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36
x-client-data: CKO1yQEIiLbJAQimtskBCMG2yQEIqZ3KAQi3qsoBCMuuygEIz6/KAQi8sMoBCJe1ygEI7bXKAQiNusoBGKukygEYvrrKAQ==
and in Firefox:
Host: books.google.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0
Accept: image/webp,/
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://catalog.libraryguardians.com/
DNT: 1
Pragma: no-cache
Cache-Control: no-cache
On the one hand… the Referer now contains only the base URL of the catalog. I believe this is due to a difference in how Koha figures out the correct image URL. When using Amazon for cover images, the ISBN of the title is normalized and used to construct a URL for an <img> tag. Koha doesn’t currently set a Referrer-Policy, so the default of no-referrer-when-downgrade is used and the full referrer is sent. Google Book’s cover image URLs cannot be directly constructed like that, so a bit of JavaScript queries a web service and gets back the image URLs, and for reasons that are unclear to me at the moment, doesn’t send the full URL as the referrer. (Cover images from OpenLibrary are fetched in a similar way, but full Referer header is sent.)
As a side note, the x-client-data header sent by Chrome to books.google.com is… concerning.
There are some relatively simple things that can be done to limit leaking the full referring URL to the likes of Google and Amazon, including
- Setting the Referrer-Policy header via web server configuration or meta tag to something like
originororigin-when-cross-origin. - Setting
referrerpolicyfor<script>and<img>tags involved in fetching book jackets.
This would help, but only up to a point: fetching https://books.google.com/books/content?id=wdgrJQAACAAJ&printsec=frontcover&img=1&zoom=5 still tells Google that a web browser at your IP address has done something to fetch the book jacket image for The Anarchist Cookbook. Suspicious!
What to do? Ultimately, if we’re going to use free third-party services to provide cover images for library catalogs, our options to do so in a way that preserves patron privacy boil down to:
- Only use sources that we trust to not broadcast or misuse the information that gets sent in the course of requesting the images. The Open Library might qualify, but ultimately isn’t beholden to any particular library that uses its data.
- Proxy image requests through the library catalog server. Evergreen does this in some cases, and it wouldn’t be much work to have Koha do something similar. It should be noted that Coce does not help in the case of Koha, as all it does is proxy image URLs, meaning that it’s still the user’s web browser fetching the actual images.
- Figure out a way to obtain local copies of the cover images and serve them from the library’s web server. Sometimes this is necessary anyway for libraries that collect stuff that wasn’t commercially sold in the past couple decades, but otherwise this is a lot of work.
- Do nothing and figure that Amazon and Google aren’t trawling through their logs correlate cover image retrieval with the potential reading interests. I actually have a tiny bit of sympathy to that approach — it’s not beyond the realm of possibility that cover image access logs are simply getting ignored, unlike say, direct usage data from Kindle or Google Books — but ostriches sticking their head in the sand are not known as a good model for due diligence.
Non-free book jacket and added content services are also an option, of course — and at least unlike Google and Amazon, it’s plausible that libraries could insist on contracts (with teeth) that forbid misuse of patron information.
My thanks to Callan Bignoli for the tweet that inspired this ramble.